
گزارش سال ۲۰۲۴ شاخص هوش مصنوعی نشان میدهد که چه چیزی باید در مورد این فناوری تغییر کند.
به گزارش سلام نو به نقل از ایسنا، درست است که هوش مصنوعی در بسیاری از موارد نسبت به انسان عملکرد بهتری از خود نشان داده است، اما رشد سریع آن به این معنی است که هوش مصنوعی برای خودش مشکلاتی نیز ایجاد کرده است و ما در مورد آن نگران هستیم.
بسیار در مورد تکامل باورنکردنی هوش مصنوعی از نظر عملکرد آن در برابر انسان صحبت میشود. تقریباً در سراسر جهان، هوش مصنوعی در طیف وسیعی از وظایف مبتنی بر عملکرد از انسان پیشی گرفته است که نیاز به توسعه معیارهای جدید و چالش برانگیزتر دارد. مسلماً این درجه از توسعه را میتوان با برچسب «خوب» طبقهبندی کرد، اما این گزارش به روی دیگر سکه در مورد تکامل سریع هوش مصنوعی میپردازد.
گزارش شاخص هوش مصنوعی ۲۰۲۴(۲۰۲۴ AI Index) که به تازگی توسط موسسه هوش مصنوعی انسان محور(HAI) دانشگاه استنفورد منتشر شده است، به شکل جامع تأثیر جهانی هوش مصنوعی را بررسی میکند. ویرایش هفتم این گزارش سالانه محتوای بیشتری نسبت به نسخههای قبلی دارد که منعکسکننده تکامل سریع هوش مصنوعی و اهمیت رو به رشد آن در زندگی روزمره ماست.
این گزارش ۵۰۰ صفحهای که توسط یک تیم میانرشتهای متشکل از کارشناسان دانشگاهی و صنعتی نوشته شده است، نگاهی مستقل و بیطرفانه به سلامت هوش مصنوعی ارائه میدهد. به گفته آنان، ما قبلاً در مورد خوبیهای رشد سریع هوش مصنوعی صحبت کردهایم و اکنون زمان آن است که با عواقب نگران کننده آن مقابله کنیم.
با توجه به اینکه هوش مصنوعی اکنون در بسیاری از جنبههای زندگی ما ادغام شده است، باید مسئولیت مشارکت خود را به ویژه در بخشهای مهمی مانند آموزش، مراقبتهای بهداشتی و مالی بر عهده بگیرد. بله، استفاده از هوش مصنوعی میتواند مزایایی را به همراه داشته باشد، برای مثال، بهینهسازی فرآیندها و بهرهوری و کشف داروهای جدید، اما خطراتی نیز به همراه دارد.
به طور خلاصه، نیاز به استفاده درست از آن است و البته بخش زیادی از این مسئولیت بر عهده توسعه دهندگان است.
هوش مصنوعی مسئول چیست و چگونه سنجیده میشود؟
بر اساس گزارش جدید AI Index، مدلهای هوش مصنوعی واقعاً مسئولانه باید انتظارات عمومی را در زمینههای کلیدی نظیر حریم خصوصی دادهها، حاکمیت دادهها، امنیت و ایمنی، عدالت، شفافیت و توضیحپذیری برآورده کنند.
حریم خصوصی دادهها از محرمانه بودن، ناشناس بودن و دادههای شخصی یک فرد محافظت میکند. این شامل حق رضایت و اطلاع از استفاده از داده است. حاکمیت داده نیز شامل سیاستها و رویههایی است که کیفیت دادهها را با تمرکز بر استفاده اخلاقی تضمین میکند. همچنین امنیت و ایمنی شامل اقداماتی است که قابلیت اطمینان سیستم را تضمین میکند و خطر سوء استفاده از دادهها، تهدیدات سایبری و خطاهای ذاتی سیستم را به حداقل میرساند.
عدالت و انصاف نیز به معنای استفاده از الگوریتمهایی است که از تعصب و تبعیض جلوگیری میکند و با مفاهیم گستردهتر اجتماعی از برابری همسو میشود. شفافیت هم به اشتراک گذاری آشکار منابع داده و تصمیمات الگوریتمی و همچنین در نظر گرفتن نحوه نظارت و مدیریت سیستمهای هوش مصنوعی از ایجاد تا عملیات گفته میشود. در آخر، توضیح پذیری به معنای توانایی توسعه دهندگان برای توضیح منطق انتخابهای مرتبط با هوش مصنوعی به زبان قابل فهم است.
پژوهشگران دانشگاه استنفورد برای گزارش امسال با شرکت اکسنچر(Accenture) همکاری کردند تا از پاسخ دهندگان در بیش از ۱۰۰۰ سازمان در سراسر جهان نظرسنجی کنند و از آنها پرسیدند که کدام خطرات را مرتبط میدانند.
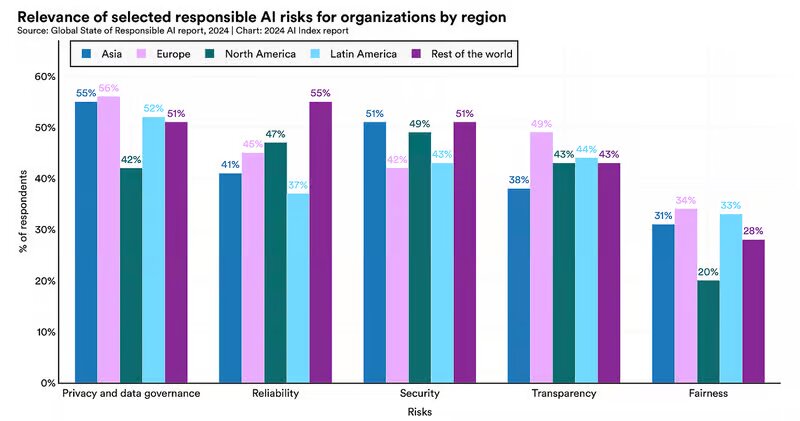
همانطور که نمودار بالا نشان میدهد، خطرات مربوط به حریم خصوصی دادهها و حاکمیت بالاترین نگرانی جهانی بوده است. با این حال، پاسخ دهندگان آسیایی(۵۵٪) و اروپایی(۵۶٪) نسبت به پاسخ دهندگان از آمریکای شمالی(۴۲٪) بیشتر در مورد این خطرات نگران هستند.
در حالی که در سطح جهانی، سازمانها کمترین نگرانی را در مورد خطرات ناشی از عدالت داشتند، تفاوت فاحشی بین پاسخدهندگان آمریکای شمالی(۲۰%) و آسیایی(۳۱%) و اروپا(۳۴%) وجود دارد.
همچنین تعداد کمی از سازمانها اقداماتی را برای کاهش خطرات مرتبط با جنبههای کلیدی هوش مصنوعی مسئول اجرا کردهاند که بررسیها ۱۸ درصد از شرکتها در اروپا، ۱۷ درصد در آمریکای شمالی و ۲۵ درصد از شرکتهای آسیایی را نشان میدهد.
کدام مدل هوش مصنوعی قابل اعتمادتر است؟
مسئولیت شامل قابلیت اعتماد است. بنابراین شاید جالب باشد که بدانیم این گزارش شاخص هوش مصنوعی کدام مدل زبان بزرگ(LLM) را قابل اعتمادتر یافته است؟
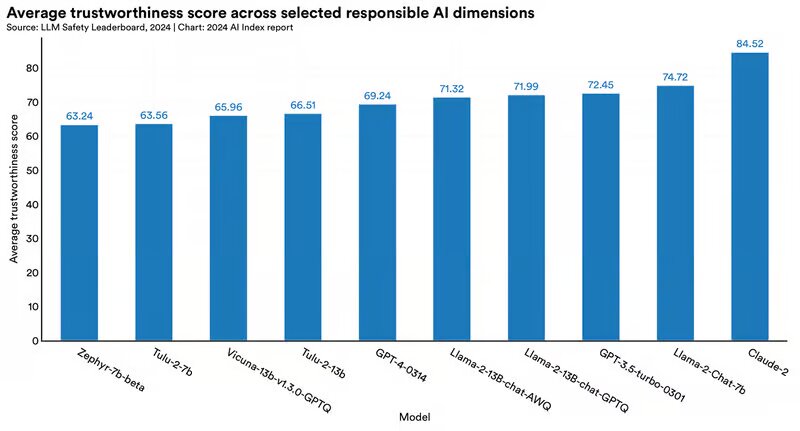
تا آنجا که به قابلیت اعتماد کلی مربوط میشود، این گزارش بر پایه DecodingTrust، یک معیار جدید است که مدلهای زبانی بزرگ را بر اساس طیف وسیعی از معیارهای هوش مصنوعی ارزیابی میکند.
مدل زبان بزرگ کلاد ۲(Claude ۲) با امتیاز قابلیت اطمینان ۸۴.۵۲ به عنوان «ایمنترین مدل» شناخته شد. پس از مدل زبان بزرگ لاما ۲(Llama ۲) با امتیاز ۷۴.۷۲ قرار گرفت و مدل زبان بزرگ GPT-۴ با امتیاز ۶۹.۲۴ سوم شد.
این گزارش میگوید که این امتیازها آسیبپذیریهای مدلهای نوع GPT، به ویژه تمایل آنها به تولید خروجیهای مغرضانه و افشای اطلاعات خصوصی از مجموعه دادهها و تاریخچه مکالمه را برجسته میکند.
افکار عمومی تغییر کرده است: نیمی از ما در مورد تأثیر هوش مصنوعی نگران هستیم
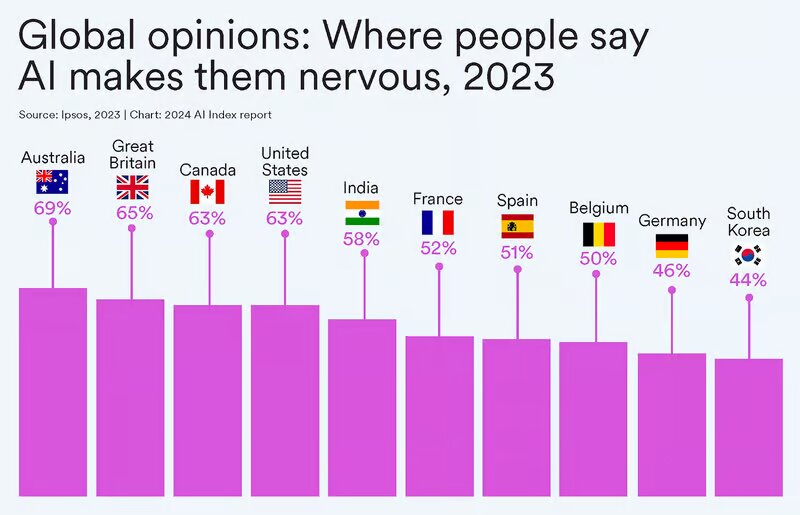
بر اساس نظرسنجیهای انجام شده، در حالی که ۵۲ درصد از مردم جهان نسبت به محصولات و خدماتی که از هوش مصنوعی استفاده میکنند، ابراز نگرانی کردهاند، استرالیاییها نگرانترین مردم هستند و پس از آنها بریتانیاییها، کاناداییها و آمریکاییها قرار دارند.
در سطح جهانی، ۵۷ درصد از مردم انتظار دارند که هوش مصنوعی طی پنج سال آینده نحوه انجام کارهایشان را تغییر دهد و بیش از یک سوم(۳۶ درصد) انتظار دارند که هوش مصنوعی در همین بازه زمانی جایگزین آنها شود.
قابل درک است که نسلهای قدیمیتر نسبت به نسلهای جوانتر کمتر نگران این هستند که هوش مصنوعی تأثیر قابل توجهی داشته باشد.
«دادههای افکار عمومی جهانی درباره هوش مصنوعی»(GPO-AI) ارائه شده در گزارش «تأثیر هوش مصنوعی» نشان میدهد که ۴۹ درصد از شهروندان جهانی بیش از همه نگران این هستند که در چند سال آینده، هوش مصنوعی مورد سوءاستفاده قرار گیرد یا برای اهداف پلید استفاده شود. ۴۵ درصد نیز نگران بودند که از آن برای نقض حریم خصوصی افراد استفاده شود.
طبق این گزارش، مردم کمتر نگران دسترسی نابرابر به هوش مصنوعی(۲۶٪) و پتانسیل آن برای سوگیری و تبعیض(۲۴٪) بودند.
به شکل مشخص در مورد ایالات متحده، دادههای مرکز تحقیقات پیو(Pew) نشان داد که تعداد بسیار بیشتری از آمریکاییها بیشتر نگران فناوری هوش مصنوعی هستند تا اینکه نسبت به آن هیجانزده باشند. این آمار از ۳۷ درصد در سال ۲۰۲۱ به ۵۲ درصد در سال ۲۰۲۳ افزایش یافته است.
خطرات سوء استفاده اخلاقی
سوء استفادههای اخلاقی از هوش مصنوعی شامل مواردی مانند خودروهای خودران که میتوانند عابران پیاده را قربانی کنند یا نرمافزار تشخیص چهرهای است که منجر به دستگیری غیرقانونی میشود. این نوع آسیبها میتوانند روی دهند و اتفاق میافتند.
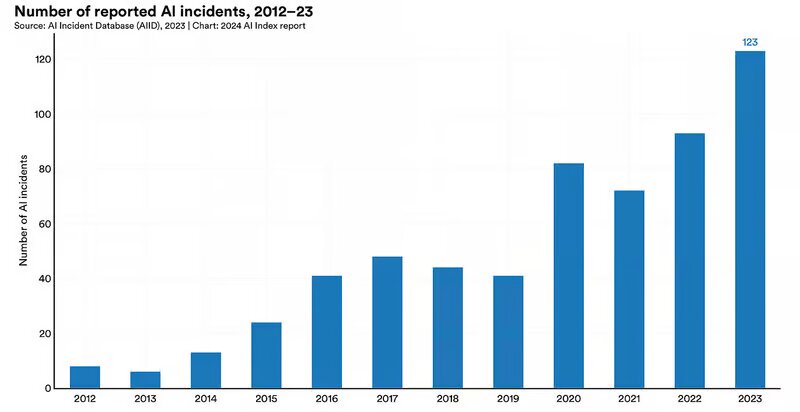
این گزارش خاطرنشان میکند که از سال ۲۰۱۳ تاکنون، حوادث مربوط به هوش مصنوعی بیش از ۲۰ برابر شده است و سال ۲۰۲۳ در مقایسه با سال ۲۰۲۲ شاهد افزایش ۳۲.۳ درصدی در حوادث هوش مصنوعی بودهایم. در ادامه فهرستی از حوادث قابل توجه اخیر آمده است که سوء استفاده از هوش مصنوعی را برجسته میکند:
ژانویه ۲۰۲۴: تصاویر مستهجن جعلی از تیلور سوئیفت خواننده سرشناس آمریکایی که توسط هوش مصنوعی ایجاد شده بود در شبکه اجتماعی ایکس(توییتر سابق) منتشر شد و قبل از حذف بیش از ۴۵ میلیون بازدید گرفت.
مه ۲۰۲۳: یک تسلا در حالت رانندگی کاملا خودران(FSD) یک عابر پیاده را در خط عابر پیاده تشخیص میدهد، اما سرعتش را کم نمیکند.
نوامبر ۲۰۲۳: یک تسلا در حالت کاملا خودران به طور ناگهانی در بزرگراه سانفرانسیسکو ترمز کرد که منجر به برخورد زنجیرهای هشت خودرو شد.
فوریه ۲۰۲۴: هانس فون اوهاین کارمند تسلا وقتی خودروی تسلای او که در حالت رانندگی خودران در حال حرکت بود، از جاده منحرف شد و به یک درخت برخورد کرد و آن را از ریشه درآورد و شعلهور شد. وی بر اثر این حادثه جان باخت، البته مشخص شد در حالت مستی پشت فرمان نشسته بوده است.
فوریه ۲۰۲۴: چتباتهای عاشقانه هوش مصنوعی مانند EVA AI Chat Bot & Soulmate، چای(Chai) و CrushOn.AI اطلاعات خصوصی زیادی را در مورد کاربران خود از جمله سلامت جنسی آنها جمعآوری کردند و ۹۰ درصد از آنها به اندازه کافی برای حفظ عدم افشای این دادهها تلاش نکردند.
خروجی محتوای مضر و نادرست
همانطور که قابلیتهای مدلهای زبانی بزرگ گسترش مییابد، احتمال استفاده نادرست از آنها نیز افزایش مییابد.
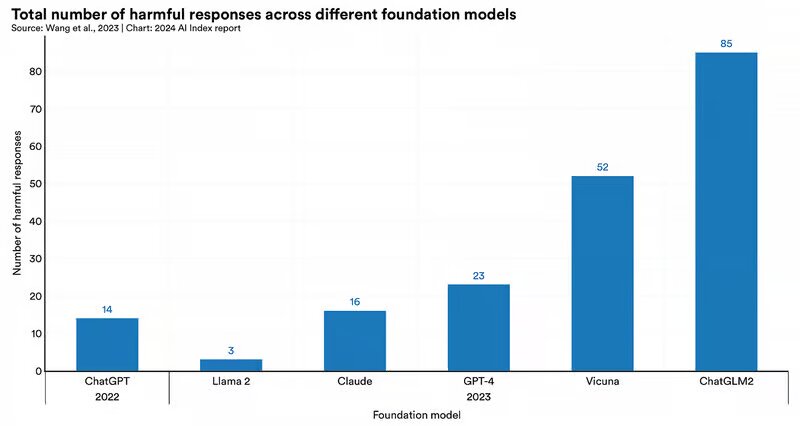
پژوهشگران مجموعه دادهای را برای ارزیابی جامع خطرات ایمنی در شش مدل زبان بزرگ برجسته شامل GPT-۴، ChatGPT، Claude، Llama ۲، Vicuna و ChatGLM۲ (یک مدل چت چینی-انگلیسی منبع باز) ایجاد کردند. آنها دریافتند که اکثر آنها تا حدی محتوای مضر تولید میکنند. ChatGPT و GPT-۴ مستعد خروجی تبعیض آمیز و توهین آمیز بودند و کلاد به انتشار اطلاعات نادرست علاقه داشت.
مدل ChatGLM۲ بیشترین تعداد تخلفات را در تقریباً همه گروههای خطر از جمله آسیبهای تعامل انسان و ربات، پاسخهای تند، تبعیضآمیز یا توهینآمیز و اطلاعات نادرست ایجاد کرد.
مطالعهای که توسط پژوهشگران آمریکایی و کانادایی انجام شد، پاسخهای مدلهای Bard، GPT-۳.۵، Claude و GPT-۴ را به سؤالات پزشکی مبتنی بر نژاد، به عنوان مثال در مورد تفاوتهای ضخامت پوست بین پوست سیاه و سفید بررسی کرد.
اگرچه پاسخهای آنها متفاوت بود، اما پژوهشگران دریافتند که همه مدلها سوگیری پزشکی مبتنی بر نژاد را از خود نشان میدهند و کلاد بیش از همه متمایز بود. پژوهشگران به این نتیجه رسیدند که این مدلهای زبانی بزرگ میتوانند تفکرات بیارزش و نژادپرستانه را تداوم بخشند.
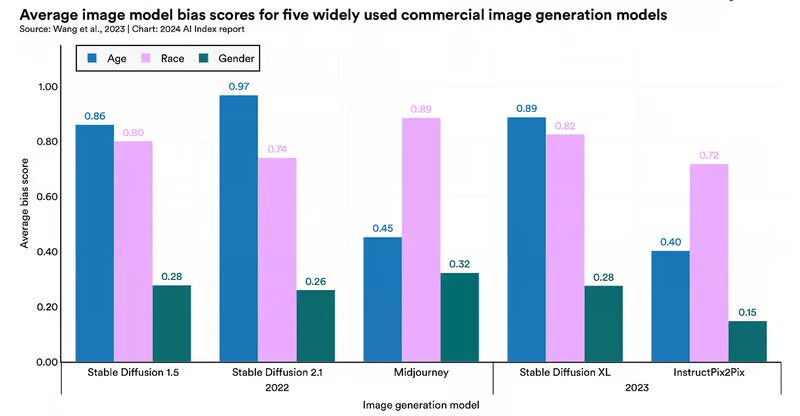
پژوهشگران در گزارش شاخص هوش مصنوعی با بررسی تصاویر تولید شده توسط هوش مصنوعی دریافتند که پنج مدل تجاری میدجرنی(Midjourney)، استیبل دیفیوژن ۱.۵(Stable Diffusion ۱.۵)، استیبل دیفیوژن ۲.۱(Stable Diffusion ۲.۱)، استیبل دیفیوژن ایکسال(Stable Diffusion XL) و اینستراکت پیکس۲پیکس(InstructPix۲Pix) تصاویری را تولید کردند که از نظر سن، نژاد و جنسیت(به ویژه نژاد و سن) مغرضانه بودند.
تاثیر محیطی خوب و بد هوش مصنوعی
بر اساس گزارش شاخص هوش مصنوعی ۲۰۲۴، هزینه زیست محیطی آموزش سیستمهای هوش مصنوعی متفاوت است و در مورد برخی از مدلها، این هزینه سنگین است. به عنوان مثال، مدل لاما ۲(Llama ۲) توسعه یافته توسط شرکت متا موجب انتشار تقریباً ۲۹۱ تن کربن شده است. این میزان ۲۹۱ برابر بیشتر از انتشار گازهای گلخانهای منتشر شده حاصل از سفر هوایی یک مسافر در یک پرواز رفت و برگشت از نیویورک به سانفرانسیسکو و ۱۶ برابر بیشتر از میانگین انتشار کربن سالانه هر شهروند آمریکایی است.
با این حال، این میزان در مقایسه با ۵۰۲ تن کربنی که در طول آموزش GPT-۳ منتشر شده است، قابل مقایسه نیست.
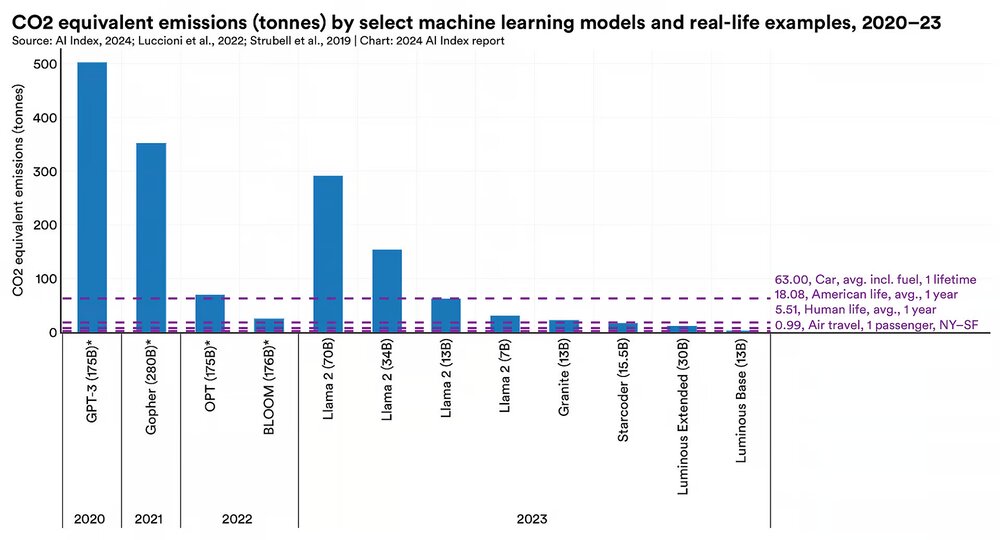
تغییرات در دادههای انتشار کربن ناشی از عواملی مانند اندازه مدل زبان بزرگ و کارایی انرژی مرکز داده است و نویسندگان گزارش خاطرنشان میکنند که بیشتر توسعه دهندگان مدلهای برجسته از جمله شرکت اوپنایآی(OpenAI)، گوگل و انتروپیک(Anthropic) انتشار کربن تولید شده در طول آموزش را گزارش نمیکنند که همین امر، انجام یک ارزیابی کامل را دشوار میکند. به عنوان مثال پژوهشگران مستقل خودشان رقم انتشار کربن مرتبط با آموزش GPT-۳ را در بند بالا تخمین زدند، زیرا توسعه دهندگان ارقام واقعی را فاش نکردهاند.
میتوان گفت که تأثیر زیستمحیطی آموزش هوش مصنوعی تا حدودی با موارد استفاده مثبت از آن برای کمک به پایداری محیطزیست جبران شده است. این گزارش نمونههایی را فهرست میکند که شامل بهینهسازی مصرف انرژی مرتبط با تهویه هوا و سنجش و پیشبینی کیفیت هوا در شهرها و صرفهجویی در زمان و هزینههای مرتبط با نظارت و مرتبسازی زباله و تبدیل زباله به انرژی است.
معضل تمام شدن دادههای آموزشی
مدلهای یادگیری ماشینی بخشهای پیچیدهای از فناوری هستند که برای یافتن الگوها یا پیشبینی از مجموعه دادههایی که قبلاً دیده نشده بودند، طراحی شدهاند. مدلهای یادگیری ماشینی برخلاف برنامههای مبتنی بر قانون که نیاز به کدگذاری صریح دارند، با ورود دادههای آموزشی جدید به سیستم تکامل مییابند.
پارامترها که مقادیر عددی آموخته شده در طول آموزش هستند که تعیین میکنند یک مدل چگونه دادههای ورودی را تفسیر و پیشبینی کند، مدلهای یادگیری ماشینی را هدایت میکنند. مدلهایی که بر روی دادههای بیشتر آموزش داده میشوند معمولاً پارامترهای بیشتری نسبت به مدلهایی که با دادههای کمتری آموزش داده میشوند، دارند. به همین شکل، مدلهایی با پارامترهای بیشتر معمولاً از مدلهایی که پارامترهای کمتری دارند، بهتر عمل میکنند.
مدلهای هوش مصنوعی بزرگی که بر روی مجموعه دادههای عظیم آموزش داده شدهاند، مانند GPT-۴ یا Claude ۳ یا جمینای(Google's) متعلق به گوگل، «مدلهای بنیادی» نامیده میشوند.

گزارش ۲۰۲۴ AI Index اشاره میکند که تعداد پارامترها به ویژه در صنعت از اوایل دهه ۲۰۱۰ به شدت افزایش یافته است که نشان دهنده پیچیدگی وظایف انجام شده توسط این مدلها، دادههای موجود بیشتر، سخت افزار بهتر و کارایی ثابت شده مدلهای بزرگتر است.
اگر بخواهیم آن را در چشم انداز خود قرار دهیم، طبق مقالهای در سال ۲۰۲۲ که در اکونومیست منتشر شد، مدل GPT-۲ بر روی ۴۰ گیگابایت داده(۷۰۰۰ اثر داستانی منتشر نشده) آموزش داده شد و ۱.۵ میلیارد پارامتر داشت. در مقابل، مدل GPT-۳ از ۵۷۰ گیگابایت داده تغذیه کرد که چندین برابر کتابها و حجم خوبی از محتوای موجود در اینترنت از جمله تمام ویکیپدیا است و دارای ۱۷۵ میلیارد پارامتر بود.
با پیشرفتی که در یادگیری ماشینی مشاهده میشود، یک پرسش بزرگ مطرح میشود. اینکه آیا دادههای آموزشی مدلها در حال اتمام است؟
به گفته پژوهشگران موسسه Epoch AI که دادههای مربوط به این گزارش را ارائه کردهاند، مسئله این نیست که آیا دادههای آموزشی ما تمام میشود یا نه، بلکه این موضوع مهم است که چه زمانی این اتفاق روی میدهد.
آنها تخمین زدند که دانشمندان رایانه میتوانند ذخیره دادههای زبانی با کیفیت بالا را تا اوایل سال جاری، دادههای زبانی با کیفیت پایین را ظرف دو دهه و ذخیره دادههای تصویری را بین اواخر دهه ۲۰۳۰ و اواسط دهه ۲۰۴۰ تمام کنند.
در حالی که از لحاظ نظری، دادههای مصنوعی تولید شده توسط خود مدلهای هوش مصنوعی میتوانند برای پر کردن مجدد مخزنهای تخلیهشده داده استفاده شوند، این راهکاری ایدهآل نیست، زیرا نشان داده شده است که منجر به فروپاشی مدل میشود.
تحقیقات همچنین نشان داده است که مدلهای مولد تصویری که صرفاً بر روی دادههای مصنوعی آموزش داده شدهاند، افت قابلتوجهی را در کیفیت خروجی نشان میدهند.
گام بعدی چیست؟
همانطور که در گزارش شاخص هوش مصنوعی آمده است، سرعت روزافزون تکامل هوش مصنوعی خطراتی را به همراه داشته است. به نظر میرسد در حالی که برخی از قابلیتهای شگفتانگیز هوش مصنوعی در حال نمایان شدن هستند، بسیاری درباره آن، به ویژه از نظر تأثیر هوش مصنوعی بر اشتغال، حریم خصوصی و امنیت نگران هستند.
گزارشی مانند شاخص هوش مصنوعی ما را قادر میسازد تا روی نبض هوش مصنوعی انگشت بگذاریم و امیدواریم همه چیز را در چشم انداز خود داشته باشیم.
خواندن گزارش سال آینده جالب خواهد بود تا ببینیم تکامل هوش مصنوعی چقدر خوب و چقدر بد بوده است.
انتهای پیام







نظر شما